
PostgreSQL - PostgreSQL
![La base de données relationnelle open source la plus avancée au monde[1]](https://wikipedia.org/wiki/File:Postgresql_elephant.svg) La base de données relationnelle open source la plus avancée au monde
| |
| Développeur(s) | Groupe de développement mondial PostgreSQL |
|---|---|
| Première version | 8 juillet 1996 |
| Version stable | 14.0 |
| Dépôt | |
| Écrit en | C |
| Système opérateur | macOS , Windows , Linux , FreeBSD , OpenBSD |
| Taper | SGBDR |
| Licence | Licence PostgreSQL ( gratuite et open-source , permissive ) |
| Site Internet |
www |
| Éditeur | PostgreSQL Global Development Group Regents de l'Université de Californie |
|---|---|
| Compatibilité Debian FSG | Oui |
| Approuvé par la FSF | Oui |
| Approuvé par l' OSI | Oui |
| Compatible GPL | Oui |
| Copyleft | Non |
| Liaison à partir du code avec une licence différente | Oui |
| Site Internet | postgresql |
PostgreSQL ( / p oʊ s t ɡ r ɛ s ˌ k Jû ɛ l / , Pohst -gres kyoo el ), également connu sous le Postgres , est libre et open-source du système de gestion de base de données relationnelle (SGBDR) mettant l' accent sur l' extensibilité et SQL conformité . Il s'appelait à l'origine POSTGRES, en référence à ses origines en tant que successeur de la base de données Ingres développée à l' Université de Californie à Berkeley . En 1996, le projet a été renommé PostgreSQL pour refléter sa prise en charge de SQL . Après une révision en 2007, l'équipe de développement a décidé de conserver le nom PostgreSQL et l'alias Postgres.
PostgreSQL dispose d' opérations avec atomicité, cohérence, isolation, durabilité propriétés (acide), automatiquement actualisables vues , vues matérialisées , les déclencheurs , les clés étrangères et les procédures stockées . Il est conçu pour gérer une gamme de charges de travail, des machines uniques aux entrepôts de données ou aux services Web avec de nombreux utilisateurs simultanés . C'est la base de données par défaut pour macOS Server et est également disponible pour Windows , Linux , FreeBSD et OpenBSD .
Histoire
PostgreSQL a évolué à partir du projet Ingres de l'Université de Californie à Berkeley. En 1982, le leader de l'équipe Ingres, Michael Stonebraker , quitte Berkeley pour créer une version propriétaire d'Ingres. Il est retourné à Berkeley en 1985 et a commencé un projet post-Ingres pour résoudre les problèmes des systèmes de bases de données contemporains qui étaient devenus de plus en plus clairs au début des années 1980. Il a remporté le prix Turing en 2014 pour ces projets et d'autres, et les techniques les ont pionnières.
Le nouveau projet, POSTGRES, visait à ajouter le moins de fonctionnalités nécessaires pour prendre complètement en charge les types de données . Ces fonctionnalités comprenaient la possibilité de définir des types et de décrire complètement les relations - quelque chose de largement utilisé, mais entièrement maintenu par l'utilisateur. Dans POSTGRES, la base de données comprenait les relations et pouvait récupérer des informations dans des tables liées de manière naturelle à l'aide de règles . POSTGRES a utilisé de nombreuses idées d'Ingres, mais pas son code.
À partir de 1986, des articles publiés ont décrit la base du système, et une version prototype a été présentée à la conférence ACM SIGMOD de 1988 . L'équipe a publié la version 1 pour un petit nombre d'utilisateurs en juin 1989, suivie de la version 2 avec un système de règles réécrit en juin 1990. La version 3, publiée en 1991, a de nouveau réécrit le système de règles et ajouté la prise en charge de plusieurs gestionnaires de stockage et un moteur de requête amélioré. En 1993, le nombre d'utilisateurs a commencé à submerger le projet de demandes de support et de fonctionnalités. Après la sortie de la version 4.2 le 30 juin 1994 – principalement un nettoyage – le projet s'est terminé. Berkeley a publié POSTGRES sous une variante de licence MIT , qui a permis à d'autres développeurs d'utiliser le code pour n'importe quel usage. À l'époque, POSTGRES utilisait un interpréteur de langage de requête POSTQUEL influencé par Ingres , qui pouvait être utilisé de manière interactive avec une application console nommée monitor.
En 1994, les étudiants diplômés de Berkeley, Andrew Yu et Jolly Chen, ont remplacé l'interpréteur du langage de requête POSTQUEL par un autre pour le langage de requête SQL, créant ainsi Postgres95. La monitorconsole a également été remplacée par psql. Yu et Chen ont annoncé la première version (0.01) aux bêta-testeurs le 5 mai 1995. La version 1.0 de Postgres95 a été annoncée le 5 septembre 1995, avec une licence plus libérale qui permettait au logiciel d'être librement modifiable.
Le 8 juillet 1996, Marc Fournier de Hub.org Networking Services a fourni le premier serveur de développement non universitaire pour l'effort de développement open source. Avec la participation de Bruce Momjian et Vadim B. Mikheev, les travaux ont commencé pour stabiliser le code hérité de Berkeley.
En 1996, le projet a été renommé PostgreSQL pour refléter sa prise en charge de SQL. La présence en ligne sur le site Web PostgreSQL.org a commencé le 22 octobre 1996. La première version de PostgreSQL a formé la version 6.0 le 29 janvier 1997. Depuis lors, les développeurs et les bénévoles du monde entier ont maintenu le logiciel sous le nom de PostgreSQL Global Development Group.
Le projet continue de rendre les versions disponibles sous sa licence de logiciel libre et open source PostgreSQL. Le code provient des contributions de fournisseurs propriétaires, de sociétés de support et de programmeurs open source.
Contrôle de simultanéité multiversion (MVCC)
PostgreSQL gère la concurrence via le contrôle de concurrence multiversion (MVCC), qui donne à chaque transaction un "instantané" de la base de données, permettant d'apporter des modifications sans affecter les autres transactions. Cela élimine en grande partie le besoin de verrous en lecture et garantit que la base de données respecte les principes ACID . PostgreSQL propose trois niveaux d' isolation des transactions : Read Committed, Repeatable Read et Serializable. Étant donné que PostgreSQL est immunisé contre les lectures modifiées, la demande d'un niveau d'isolement de transaction en lecture non validée fournit à la place une validation en lecture. PostgreSQL prend en charge la sérialisabilité complète via la méthode d' isolation d'instantané sérialisable (SSI).
Stockage et réplication
Réplication
PostgreSQL inclut une réplication binaire intégrée basée sur l'envoi des modifications ( journaux d'écriture anticipée (WAL)) aux nœuds de réplication de manière asynchrone, avec la possibilité d'exécuter des requêtes en lecture seule sur ces nœuds répliqués. Cela permet de répartir efficacement le trafic de lecture entre plusieurs nœuds. Les logiciels de réplication antérieurs qui permettaient une mise à l'échelle de lecture similaire reposaient normalement sur l'ajout de déclencheurs de réplication au maître, ce qui augmentait la charge.
PostgreSQL comprend une réplication synchrone intégrée qui garantit que, pour chaque transaction d'écriture, le maître attend qu'au moins un nœud de réplique ait écrit les données dans son journal de transactions. Contrairement à d'autres systèmes de bases de données, la durabilité d'une transaction (qu'elle soit asynchrone ou synchrone) peut être spécifiée par base de données, par utilisateur, par session ou même par transaction. Cela peut être utile pour les charges de travail qui ne nécessitent pas de telles garanties, et peut ne pas être souhaité pour toutes les données car cela ralentit les performances en raison de l'exigence de la confirmation de la transaction atteignant la veille synchrone.
Les serveurs de secours peuvent être synchrones ou asynchrones. Des serveurs de secours synchrones peuvent être spécifiés dans la configuration qui détermine quels serveurs sont candidats à la réplication synchrone. Le premier de la liste qui diffuse activement sera utilisé comme serveur synchrone actuel. En cas d'échec, le système bascule vers le suivant.
La réplication multimaître synchrone n'est pas incluse dans le noyau PostgreSQL. Postgres-XC qui est basé sur PostgreSQL fournit une réplication multi-maîtres synchrone évolutive. Il est licencié sous la même licence que PostgreSQL. Un projet connexe s'appelle Postgres-XL . Postgres-R est encore un autre fork . La réplication bidirectionnelle (BDR) est un système de réplication multi-maître asynchrone pour PostgreSQL.
Des outils tels que repmgr facilitent la gestion des clusters de réplication.
Plusieurs packages de réplication basés sur des déclencheurs asynchrones sont disponibles. Celles-ci restent utiles même après l'introduction des capacités de base étendues, pour les situations où la réplication binaire d'un cluster de bases de données complet est inapproprié :
- Slony-I
- Londiste, partie de SkyTools (développé par Skype )
- Réplication multi-maître Bucardo (développée par Backcountry.com )
- Réplication multi-maîtres et multi-niveaux SymmetricDS
YugabyteDB est une base de données qui utilise le front-end de PostgreSQL avec un backend plus proche de NoSQL . Bien qu'il puisse être considéré comme une base de données différente, il s'agit essentiellement de PostgreSQL avec un backend de stockage différent. Il aborde les problèmes de réplication avec une mise en œuvre des idées de Google Spanner . De telles bases de données sont appelées NewSQL et incluent CockroachDB et TiDB entre autres.
Index
PostgreSQL inclut une prise en charge intégrée des index de table de hachage et d' arbre B standard , ainsi que quatre méthodes d'accès aux index : arbres de recherche généralisés ( GiST ), index inversés généralisés (GIN), GiST partitionné par espace (SP-GiST) et index de plage de blocs ( BRIN). De plus, des méthodes d'indexation définies par l'utilisateur peuvent être créées, bien que ce soit un processus assez complexe. Les index dans PostgreSQL prennent également en charge les fonctionnalités suivantes :
- Les index d'expression peuvent être créés avec un index du résultat d'une expression ou d'une fonction, au lieu de simplement la valeur d'une colonne.
- Les index partiels , qui n'indexent qu'une partie d'une table, peuvent être créés en ajoutant une clause WHERE à la fin de l'instruction CREATE INDEX. Cela permet de créer un index plus petit.
- Le planificateur est capable d'utiliser plusieurs index ensemble pour répondre à des requêtes complexes, en utilisant des opérations d' index bitmap temporaires en mémoire (utiles pour les applications d' entrepôt de données pour joindre une grande table de faits à des tables de dimensions plus petites telles que celles organisées dans un schéma en étoile ).
- L' indexation k - plus proches voisins ( k -NN) (également appelée KNN-GiST) fournit une recherche efficace des "valeurs les plus proches" de celles spécifiées, utile pour trouver des mots similaires, ou fermer des objets ou des emplacements avec des données géospatiales . Ceci est réalisé sans correspondance exhaustive des valeurs.
- Les analyses d'index uniquement permettent souvent au système de récupérer des données à partir d'index sans jamais avoir à accéder à la table principale.
- Indices de plage de blocs (BRIN).
Schémas
Dans PostgreSQL, un schéma contient tous les objets, à l'exception des rôles et des tablespaces. Les schémas agissent effectivement comme des espaces de noms, permettant aux objets du même nom de coexister dans la même base de données. Par défaut, les bases de données nouvellement créées ont un schéma appelé public , mais d'autres schémas peuvent être ajoutés et le schéma public n'est pas obligatoire.
Un search_pathparamètre détermine l'ordre dans lequel PostgreSQL vérifie les schémas pour les objets non qualifiés (ceux sans schéma préfixé). Par défaut, il est défini sur $user, public( $userfait référence à l'utilisateur de base de données actuellement connecté). Cette valeur par défaut peut être définie au niveau d'une base de données ou d'un rôle, mais comme il s'agit d'un paramètre de session, il peut être librement modifié (même plusieurs fois) au cours d'une session client, affectant uniquement cette session.
Les schémas inexistants répertoriés dans search_path sont ignorés en silence lors de la recherche d'objets.
Les nouveaux objets sont créés dans le schéma valide (celui qui existe actuellement) qui apparaît en premier dans le chemin_recherche.
Types de données
Une grande variété de types de données natifs sont pris en charge, notamment :
- booléen
- Numériques de précision arbitraire
- Caractère (texte, varchar, char)
- Binaire
- Date/heure (horodatage/heure avec/sans fuseau horaire, date, intervalle)
- De l'argent
- Énumération
- Chaînes de bits
- Type de recherche de texte
- Composite
- HStore, un magasin clé-valeur activé par l'extension dans PostgreSQL
- Tableaux (longueur variable et peuvent être de n'importe quel type de données, y compris les types de texte et composites) jusqu'à 1 Go de taille de stockage totale
- Primitives géométriques
- Adresses IPv4 et IPv6
- Blocs de routage interdomaine sans classe (CIDR) et adresses MAC
- XML prenant en charge les requêtes XPath
- Identifiant universel unique (UUID)
- JavaScript Object Notation ( JSON ) et un JSONB binaire plus rapide (pas le même que BSON )
De plus, les utilisateurs peuvent créer leurs propres types de données qui peuvent généralement être rendus entièrement indexables via les infrastructures d'indexation de PostgreSQL – GiST, GIN, SP-GiST. Des exemples de ceux-ci incluent les types de données du système d'information géographique (SIG) du projet PostGIS pour PostgreSQL.
Il existe également un type de données appelé domaine , qui est le même que tout autre type de données mais avec des contraintes facultatives définies par le créateur de ce domaine. Cela signifie que toutes les données saisies dans une colonne à l'aide du domaine devront se conformer aux contraintes définies dans le cadre du domaine.
Un type de données qui représente une plage de données peut être utilisé, appelé types de plage. Il peut s'agir de plages discrètes (par exemple, toutes les valeurs entières de 1 à 10) ou de plages continues (par exemple, à tout moment entre 10h00 et 11h00 ). Les types de plage intégrés disponibles incluent des plages d'entiers, de grands entiers, de nombres décimaux, d'horodatages (avec et sans fuseau horaire) et de dates.
Des types de plages personnalisés peuvent être créés pour rendre de nouveaux types de plages disponibles, tels que des plages d'adresses IP utilisant le type inet comme base ou des plages flottantes utilisant le type de données float comme base. Les types de plage prennent en charge les limites de plage inclusives et exclusives en utilisant respectivement les caractères [/ ]et (/ ). (par exemple, [4,9)représente tous les entiers à partir de et y compris 4 jusqu'à mais sans inclure 9.) Les types de plage sont également compatibles avec les opérateurs existants utilisés pour vérifier le chevauchement, le confinement, le droit de etc.
Objets définis par l'utilisateur
De nouveaux types de presque tous les objets de la base de données peuvent être créés, notamment :
- Moulages
- Conversions
- Types de données
- Domaines de données
- Fonctions, y compris les fonctions d'agrégat et les fonctions de fenêtre
- Index comprenant des index personnalisés pour les types personnalisés
- Opérateurs (ceux qui existent peuvent être surchargés )
- Langages procéduraux
Héritage
Les tables peuvent être définies pour hériter de leurs caractéristiques d'une table parent . Les données des tables enfants sembleront exister dans les tables parent, à moins que les données ne soient sélectionnées dans la table parent à l'aide du mot clé ONLY, c'est-à-dire . L'ajout d'une colonne dans la table parent fera apparaître cette colonne dans la table enfant.
SELECT * FROM ONLY parent_table;
L'héritage peut être utilisé pour implémenter le partitionnement de table, en utilisant des déclencheurs ou des règles pour diriger les insertions vers la table parent dans les tables enfants appropriées.
En 2010, cette fonctionnalité n'est pas encore entièrement prise en charge - en particulier, les contraintes de table ne sont actuellement pas héritables. Toutes les contraintes de vérification et les contraintes non nulles sur une table parent sont automatiquement héritées par ses enfants. Les autres types de contraintes (contraintes uniques, de clé primaire et de clé étrangère) ne sont pas héritées.
L'héritage fournit un moyen de mapper les caractéristiques des hiérarchies de généralisation décrites dans les diagrammes de relation d'entité (ERD) directement dans la base de données PostgreSQL.
Autres fonctionnalités de stockage
- Intégrité référentielle contraintes , y compris des clés étrangères contraintes, colonne des contraintes et des contrôles de ligne
- Stockage binaire et textuel de gros objets
- Espaces table
- Classement par colonne
- Sauvegarde en ligne
- Récupération ponctuelle, mise en œuvre à l'aide de la journalisation en écriture anticipée
- Mises à niveau sur place avec pg_upgrade pour moins de temps d'arrêt
Contrôle et connectivité
Wrappers de données étrangères
PostgreSQL peut se lier à d'autres systèmes pour récupérer des données via des wrappers de données étrangères (FDW). Ceux-ci peuvent prendre la forme de n'importe quelle source de données, telle qu'un système de fichiers, un autre système de gestion de base de données relationnelle (SGBDR) ou un service Web. Cela signifie que les requêtes de base de données régulières peuvent utiliser ces sources de données comme des tables régulières, et même joindre plusieurs sources de données ensemble.
Interfaces
Pour se connecter aux applications, PostgreSQL inclut les interfaces intégrées libpq (l'interface officielle de l'application C) et ECPG (un système C embarqué). Des bibliothèques tierces pour se connecter à PostgreSQL sont disponibles pour de nombreux langages de programmation , notamment C++ , Java , Julia , Python , Node.js , Go et Rust .
Langages procéduraux
Les langages procéduraux permettent aux développeurs d'étendre la base de données avec des sous-routines (fonctions) personnalisées, souvent appelées procédures stockées . Ces fonctions peuvent être utilisées pour créer des déclencheurs de base de données (fonctions invoquées lors de la modification de certaines données) et des types de données personnalisés et des fonctions d'agrégation . Les langages procéduraux peuvent également être invoqués sans définir de fonction, à l'aide d'une commande DO au niveau SQL.
Les langages sont divisés en deux groupes : Les procédures écrites dans des langages sûrs sont en bac à sable et peuvent être créées et utilisées en toute sécurité par n'importe quel utilisateur. Les procédures écrites dans des langages dangereux ne peuvent être créées que par des superutilisateurs , car elles permettent de contourner les restrictions de sécurité d'une base de données, mais peuvent également accéder à des sources externes à la base de données. Certains langages comme Perl fournissent à la fois des versions sûres et dangereuses.
PostgreSQL prend en charge trois langages procéduraux intégrés :
- SQL brut (sûr). Des fonctions SQL plus simples peuvent être étendues en ligne dans la requête d'appel (SQL), ce qui économise la surcharge d'appel de fonction et permet à l'optimiseur de requête de « voir à l'intérieur » de la fonction.
- Langage procédural/PostgreSQL ( PL/pgSQL ) (sûr), qui ressemble au langage procédural Oracle's Procedural Language for SQL ( PL/SQL ) et aux modules SQL/Persistent Stored ( SQL/PSM ).
- C (unsafe), qui permet de charger une ou plusieurs bibliothèques partagées personnalisées dans la base de données. Les fonctions écrites en C offrent les meilleures performances, mais des bogues dans le code peuvent planter et potentiellement corrompre la base de données. La plupart des fonctions intégrées sont écrites en C.
De plus, PostgreSQL permet aux langages procéduraux d'être chargés dans la base de données via des extensions. Trois extensions de langage sont incluses avec PostgreSQL pour prendre en charge Perl , Tcl et Python . Pour Python, Python 2 abandonné est utilisé par défaut ( plpythonuou plpython2u), même dans PostgreSQL 14 ; Python 3 est également pris en charge en choisissant le langage plpython3u). Les projets externes prennent en charge de nombreux autres langages, notamment PL/ Java , JavaScript (PL/V8), PL/ Julia PL/ R , PL/ Ruby , et d'autres.
Déclencheurs
Les déclencheurs sont des événements déclenchés par l'action des instructions du langage de manipulation de données SQL (DML). Par exemple, une instruction INSERT peut activer un déclencheur qui vérifie si les valeurs de l'instruction sont valides. La plupart des déclencheurs ne sont activés que par les instructions INSERT ou UPDATE .
Les déclencheurs sont entièrement pris en charge et peuvent être attachés aux tables. Les déclencheurs peuvent être par colonne et conditionnels, en ce sens que les déclencheurs UPDATE peuvent cibler des colonnes spécifiques d'une table, et les déclencheurs peuvent être appelés à s'exécuter dans un ensemble de conditions comme spécifié dans la clause WHERE du déclencheur. Les déclencheurs peuvent être attachés aux vues à l'aide de la condition INSTEAD OF. Plusieurs déclencheurs sont déclenchés par ordre alphabétique. En plus d'appeler des fonctions écrites dans le PL/pgSQL natif, les déclencheurs peuvent également appeler des fonctions écrites dans d'autres langages comme PL/Python ou PL/Perl.
Notifications asynchrones
PostgreSQL fournit un système de messagerie asynchrone accessible via les commandes NOTIFY, LISTEN et UNLISTEN. Une session peut émettre une commande NOTIFY, avec le canal spécifié par l'utilisateur et une charge utile facultative, pour marquer un événement particulier qui se produit. D'autres sessions sont capables de détecter ces événements en émettant une commande LISTEN, qui peut écouter un canal particulier. Cette fonctionnalité peut être utilisée à diverses fins, par exemple pour informer d'autres sessions lorsqu'une table a été mise à jour ou pour que des applications distinctes détectent lorsqu'une action particulière a été effectuée. Un tel système évite la nécessité d'une interrogation continue par les applications pour voir si quelque chose a encore changé, et réduit les frais généraux inutiles. Les notifications sont entièrement transactionnelles, en ce sens que les messages ne sont pas envoyés tant que la transaction à partir de laquelle ils ont été envoyés n'est pas validée. Cela élimine le problème des messages envoyés pour une action en cours qui est ensuite annulée.
De nombreux connecteurs pour PostgreSQL prennent en charge ce système de notification (notamment libpq, JDBC, Npgsql, psycopg et node.js) afin qu'il puisse être utilisé par des applications externes.
PostgreSQL peut agir comme un serveur "pub/sub" ou un serveur de travaux efficace et persistant en combinant LISTEN avec FOR UPDATE SKIP LOCKED.
Règles
Les règles permettent de réécrire "l'arbre de requête" d'une requête entrante. Les « règles de réécriture des requêtes » sont attachées à une table/classe et « ré-écrivent » le DML entrant (sélectionner, insérer, mettre à jour et/ou supprimer) dans une ou plusieurs requêtes qui remplacent l'instruction DML d'origine ou s'exécutent dans en plus. La réécriture de la requête se produit après l'analyse de l'instruction DML, mais avant la planification de la requête.
Autres fonctionnalités d'interrogation
- Transactions
- Recherche en texte intégral
- Vues
- Vues matérialisées
- Vues modifiables
- Vues récursives
- Intérieur, extérieur (plein, à gauche et à droite), et la croix s'associe
- Sous- sélections
- Sous-requêtes corrélées
- Expressions régulières
- expressions de table communes et expressions de table communes accessibles en écriture
- Connexions cryptées via Transport Layer Security (TLS) ; les versions actuelles n'utilisent pas de SSL vulnérable, même avec cette option de configuration
- Domaines
- Points de sauvegarde
- Validation en deux phases
- La technique de stockage d'attributs surdimensionnés (TOAST) est utilisée pour stocker de manière transparente les grands attributs de table (tels que les grandes pièces jointes MIME ou les messages XML) dans une zone séparée, avec compression automatique.
- Embedded SQL est implémenté à l'aide d'un préprocesseur. Le code SQL est d'abord écrit intégré dans le code C. Ensuite, le code est exécuté via le préprocesseur ECPG, qui remplace SQL par des appels à la bibliothèque de code. Ensuite, le code peut être compilé à l'aide d'un compilateur C. L'intégration fonctionne également avec C++ mais elle ne reconnaît pas toutes les constructions C++.
Modèle de simultanéité
Le serveur PostgreSQL est basé sur les processus (non threadé) et utilise un processus de système d'exploitation par session de base de données. Plusieurs sessions sont automatiquement réparties sur tous les processeurs disponibles par le système d'exploitation. De nombreux types de requêtes peuvent également être parallélisés sur plusieurs processus de travail en arrière-plan, en tirant parti de plusieurs processeurs ou cœurs. Les applications clientes peuvent utiliser des threads et créer plusieurs connexions de base de données à partir de chaque thread.
Sécurité
PostgreSQL gère sa sécurité interne rôle par rôle . Un rôle est généralement considéré comme un utilisateur (un rôle qui peut se connecter) ou un groupe (un rôle dont d'autres rôles sont membres). Les autorisations peuvent être accordées ou révoquées sur n'importe quel objet jusqu'au niveau de la colonne, et peuvent également autoriser/empêcher la création de nouveaux objets au niveau de la base de données, du schéma ou de la table.
La fonction SECURITY LABEL de PostgreSQL (extension aux normes SQL) permet une sécurité supplémentaire ; avec un module chargeable fourni qui prend en charge le contrôle d'accès obligatoire basé sur des étiquettes (MAC) basé sur la politique de sécurité Security-Enhanced Linux (SELinux).
PostgreSQL prend en charge nativement un grand nombre de mécanismes d'authentification externes, notamment :
- Mot de passe : soit SCRAM-SHA-256 (depuis PostgreSQL 10), MD5 ou texte brut
- Interface de programme d'application de services de sécurité générique (GSSAPI)
- Interface du fournisseur de support de sécurité (SSPI)
- Kerberos
- ident (met en correspondance le nom d'utilisateur du système d'exploitation fourni par un serveur d'identification avec le nom d'utilisateur de la base de données)
- Pair (fait correspondre le nom d'utilisateur local au nom d'utilisateur de la base de données)
-
Protocole léger d'accès aux répertoires (LDAP)
- Annuaire actif (AD)
- RAYON
- Certificat
- Module d'authentification enfichable (PAM)
Les méthodes GSSAPI, SSPI, Kerberos, peer, ident et certificate peuvent également utiliser un fichier "map" spécifié qui répertorie les utilisateurs correspondant à ce système d'authentification qui sont autorisés à se connecter en tant qu'utilisateur de base de données spécifique.
Ces méthodes sont spécifiées dans le fichier de configuration d'authentification basée sur l'hôte du cluster ( pg_hba.conf), qui détermine les connexions autorisées. Cela permet de contrôler quel utilisateur peut se connecter à quelle base de données, d'où il peut se connecter (adresse IP, plage d'adresses IP, socket de domaine), quel système d'authentification sera appliqué et si la connexion doit utiliser Transport Layer Security (TLS).
Conformité aux normes
PostgreSQL revendique une conformité élevée, mais pas complète, avec la dernière norme SQL (pour la version 13 "en septembre 2020, PostgreSQL est conforme à au moins 170 des 179 fonctionnalités obligatoires pour la conformité SQL:2016 Core", et aucune autre base de données ne s'y conforme entièrement ). Une exception est la gestion des identificateurs sans guillemets comme les noms de table ou de colonne. Dans PostgreSQL, ils sont repliés, en interne, en caractères minuscules alors que la norme dit que les identifiants sans guillemets doivent être repliés en majuscules. Ainsi, Foodevrait être équivalent à FOOnon fooconforme à la norme.
Benchmarks et performances
De nombreuses études informelles sur les performances de PostgreSQL ont été réalisées. Les améliorations de performances visant à améliorer l'évolutivité ont commencé fortement avec la version 8.1. Des benchmarks simples entre la version 8.0 et la version 8.4 ont montré que cette dernière était plus de 10 fois plus rapide sur les charges de travail en lecture seule et au moins 7,5 fois plus rapide sur les charges de travail en lecture et en écriture.
Le premier benchmark conforme aux normes de l'industrie et validé par les pairs a été réalisé en juin 2007, en utilisant le serveur d'applications Sun Java System (version propriétaire de GlassFish ) 9.0 Platform Edition, le serveur Sun Fire basé sur UltraSPARC T1 et PostgreSQL 8.2. Ce résultat de 778,14 SPECjAppServer2004 JOPS@Standard se compare avantageusement au 874 JOPS@Standard avec Oracle 10 sur un système HP-UX basé sur Itanium .
En août 2007, Sun a soumis un score de référence amélioré de 813,73 SPECjAppServer2004 JOPS@Standard. Avec le système testé à un prix réduit, le rapport prix/performances est passé de 84,98 $/JOPS à 70,57 $/JOPS.
La configuration par défaut de PostgreSQL n'utilise qu'une petite quantité de mémoire dédiée à des fins critiques en termes de performances, telles que la mise en cache des blocs de base de données et le tri. Cette limitation est principalement due au fait que les systèmes d'exploitation plus anciens nécessitaient des modifications du noyau pour permettre l'allocation de gros blocs de mémoire partagée . PostgreSQL.org fournit des conseils sur les pratiques de performances de base recommandées dans un wiki .
En avril 2012, Robert Haas d'EnterpriseDB a démontré l'évolutivité linéaire du processeur de PostgreSQL 9.2 en utilisant un serveur à 64 cœurs.
Matloob Khushi a effectué une analyse comparative entre PostgreSQL 9.0 et MySQL 5.6.15 pour leur capacité à traiter les données génomiques. Dans son analyse des performances, il a découvert que PostgreSQL extrait les régions génomiques qui se chevauchent huit fois plus rapidement que MySQL en utilisant deux ensembles de données de 80 000 chacun formant des régions aléatoires d'ADN humain. L'insertion et les téléchargements de données dans PostgreSQL étaient également meilleurs, bien que la capacité de recherche générale des deux bases de données soit presque équivalente.
Plateformes
PostgreSQL est disponible pour les systèmes d'exploitation suivants : Linux (toutes les distributions récentes), installateurs x86 64 bits disponibles et testés pour macOS (OS X) version 10.6 et plus récent – Windows (avec installateurs disponibles et testés pour Windows Server 2019 64 bits et 2016 ; certaines versions plus anciennes de PostgreSQL sont testées jusqu'à Windows 2008 R2, tandis que pour PostgreSQL version 10 et plus anciennes, un programme d'installation 32 bits est disponible et testé jusqu'à Windows 2008 R1 32 bits ; compilable par exemple par Visual Studio , version 2013 jusqu'au version la plus récente 2019) – FreeBSD , OpenBSD , NetBSD , AIX , HP-UX , Solaris et UnixWare ; et non officiellement testés : DragonFly BSD , BSD/OS , IRIX , OpenIndiana , OpenSolaris , OpenServer et Tru64 UNIX . La plupart des autres systèmes de type Unix pourraient également fonctionner ; les plus modernes prennent en charge.
PostgreSQL fonctionne sur l'une des architectures de jeu d'instructions suivantes : x86 et x86-64 sur Windows XP (ou supérieur) et d'autres systèmes d'exploitation ; ceux-ci sont pris en charge sur d'autres que Windows : IA-64 Itanium (prise en charge externe de HP-UX), PowerPC , PowerPC 64, S/390 , S/390x , SPARC , SPARC 64, ARMv8 -A ( 64 bits ) et ARM plus ancien ( 32 bits , y compris les plus anciens tels que ARMv6 dans Raspberry Pi ), MIPS , MIPSel et PA-RISC . Il était également connu pour fonctionner sur d'autres plates-formes (bien qu'il n'ait pas été testé depuis des années, c'est-à-dire pour les dernières versions).
Administration des bases de données
Les frontaux open source et les outils d'administration de PostgreSQL incluent :
- psql
- Le principal frontal pour PostgreSQL est le
psqlprogramme de ligne de commande , qui peut être utilisé pour saisir des requêtes SQL directement, ou les exécuter à partir d' un fichier. De plus, psql fournit un certain nombre de méta-commandes et diverses fonctionnalités de type shell pour faciliter l'écriture de scripts et l'automatisation d'une grande variété de tâches ; par exemple la complétion par tabulation des noms d'objet et la syntaxe SQL. - pgAdmin
- Le package pgAdmin est un outil d'administration d'interface utilisateur graphique (GUI) gratuit et open source pour PostgreSQL, qui est pris en charge sur de nombreuses plates-formes informatiques. Le programme est disponible dans plus d'une douzaine de langues. Le premier prototype, nommé pgManager, a été écrit pour PostgreSQL 6.3.2 à partir de 1998, et réécrit et publié sous le nom de pgAdmin sous la licence publique générale GNU (GPL) au cours des mois suivants. La deuxième version (nommée pgAdmin II) était une réécriture complète, publiée pour la première fois le 16 janvier 2002. La troisième version, pgAdmin III, a été initialement publiée sous la licence artistique , puis publiée sous la même licence que PostgreSQL. Contrairement aux versions précédentes écrites en Visual Basic , pgAdmin III est écrit en C++, en utilisant le framework wxWidgets lui permettant de s'exécuter sur la plupart des systèmes d'exploitation courants. L'outil de requête comprend un langage de script appelé pgScript pour prendre en charge les tâches d'administration et de développement. En décembre 2014, Dave Page, fondateur et développeur principal du projet pgAdmin, a annoncé qu'avec le passage aux modèles basés sur le Web, le travail avait commencé sur pgAdmin 4 dans le but de faciliter les déploiements dans le cloud. En 2016, pgAdmin 4 est sorti. Le backend pgAdmin 4 a été écrit en Python , en utilisant Flask et le framework Qt .
- phpPgAdmin
- phpPgAdmin est un outil d'administration Web pour PostgreSQL écrit en PHP et basé sur l' interface populaire phpMyAdmin écrite à l'origine pour l' administration MySQL .
- PostgreSQL Studio
- PostgreSQL Studio permet aux utilisateurs d'effectuer des tâches de développement de base de données PostgreSQL essentielles à partir d'une console Web. PostgreSQL Studio permet aux utilisateurs de travailler avec des bases de données cloud sans avoir besoin d'ouvrir des pare-feu.
- ÉquipePostgreSQL
- Interface Web pilotée par AJAX/JavaScript pour PostgreSQL. Permet de parcourir, de maintenir et de créer des données et des objets de base de données via un navigateur Web. L'interface propose un éditeur SQL à onglets avec saisie semi-automatique, des widgets d'édition de lignes, une navigation par clé étrangère par clic entre les lignes et les tables, la gestion des favoris pour les scripts couramment utilisés, entre autres fonctionnalités. Prend en charge SSH pour l'interface Web et les connexions à la base de données . Des programmes d'installation sont disponibles pour Windows, Macintosh et Linux, ainsi qu'une simple archive multiplateforme qui s'exécute à partir d'un script.
- LibreOffice, OpenOffice.org
- LibreOffice et OpenOffice.org Base peuvent être utilisés comme front-end pour PostgreSQL.
- pgBlaireau
- L'analyseur de journal pgBadger PostgreSQL génère des rapports détaillés à partir d'un fichier journal PostgreSQL.
- pgDevOps
- pgDevOps est une suite d'outils Web permettant d'installer et de gérer plusieurs versions, extensions et composants communautaires de PostgreSQL, de développer des requêtes SQL, de surveiller les bases de données en cours d'exécution et de trouver des problèmes de performances.
- Administrateur
- Adminer est un outil d'administration Web simple pour PostgreSQL et autres, écrit en PHP.
- pgBackRest
- pgBackRest est un outil de sauvegarde et de restauration pour PostgreSQL qui prend en charge les sauvegardes complètes, différentielles et incrémentielles.
- pgaudit
- pgaudit est une extension PostgreSQL qui fournit une journalisation détaillée d'audit de session et/ou d'objet via la fonction de journalisation standard fournie par PostgreSQL.
- wal-e
- Wal-e est un outil de sauvegarde et de restauration pour PostgreSQL qui prend en charge les sauvegardes physiques (basées sur WAL), écrites en Python
Un certain nombre d'entreprises proposent des outils propriétaires pour PostgreSQL. Ils consistent souvent en un noyau universel adapté à divers produits de bases de données spécifiques. Ces outils partagent principalement les fonctionnalités d'administration avec les outils open source mais offrent des améliorations dans la modélisation , l'importation, l'exportation ou la création de rapports de données.
Utilisateurs notables
Les organisations et produits notables qui utilisent PostgreSQL comme base de données principale incluent :
- En 2009, le site Web de réseautage social Myspace a utilisé la base de données nCluster d' Aster Data Systems pour l'entreposage de données, qui reposait sur PostgreSQL non modifié.
- Geni.com utilise PostgreSQL pour sa base de données généalogique principale.
- OpenStreetMap , un projet collaboratif pour créer une carte du monde modifiable gratuitement.
- Afilias , registres de domaines pour .org , .info et autres.
- Jeux en ligne multijoueurs en ligne de Sony .
- BASF , plateforme d'achat pour leur portail agroalimentaire.
- Site d'actualités sociales Reddit .
- Application VoIP Skype , bases de données commerciales centrales .
- Sun xVM , la suite d'automatisation de virtualisation et de centre de données de Sun.
- MusicBrainz , encyclopédie ouverte de la musique en ligne.
- La Station spatiale internationale – pour collecter des données de télémétrie en orbite et les répliquer au sol.
- Site de réseautage social MyYearbook .
- Instagram , un service mobile de partage de photos.
- Disqus , un service de discussion et de commentaires en ligne.
- TripAdvisor , site Web d'informations sur les voyages dont le contenu est principalement généré par les utilisateurs.
- Yandex , une société Internet russe a basculé son service Yandex.Mail d'Oracle vers Postgres.
- Amazon Redshift , qui fait partie d'AWS, un système de traitement analytique en ligne en colonnes (OLAP) basé sur les modifications Postgres de ParAccel .
- National Oceanic and Atmospheric Administration (NOAA) National Weather Service (NWS), Interactive Forecast Preparation System (IFPS), un système qui intègre les données des radars météorologiques NEXRAD , des systèmes de surface et hydrologiques pour créer des modèles de prévision localisés détaillés.
- Le service météorologique national du Royaume-Uni , Met Office , a commencé à remplacer Oracle par PostgreSQL dans le cadre d'une stratégie visant à déployer davantage de technologies open source.
- WhitePages.com utilisait Oracle et MySQL , mais lorsqu'il a fallu déplacer ses répertoires principaux en interne, il s'est tourné vers PostgreSQL. Étant donné que WhitePages.com doit combiner de grands ensembles de données provenant de plusieurs sources, la capacité de PostgreSQL à charger et à indexer les données à des taux élevés a été la clé de sa décision d'utiliser PostgreSQL.
- FlightAware , un site Web de suivi des vols.
- Grofers , un service de livraison d'épicerie en ligne.
- The Guardian a migré de MongoDB vers PostgreSQL en 2018.
Implémentations de services
Certains fournisseurs notables proposent PostgreSQL en tant que logiciel en tant que service :
- Heroku , une plate - forme en tant que service fournisseur, a pris en charge PostgreSQL depuis le début en 2007. Ils offrent des fonctionnalités à valeur ajoutée comme base de données complète roll-back (possibilité de restaurer une base de données à partir de tout temps spécifié), qui est basé sur WAL-E, logiciel open source développé par Heroku.
- En janvier 2012, EnterpriseDB a publié une version cloud de PostgreSQL et de son propre serveur Postgres Plus Advanced Server propriétaire avec provisionnement automatisé pour le basculement, la réplication, l'équilibrage de charge et la mise à l'échelle. Il fonctionne sur Amazon Web Services . Depuis 2015, Postgres Advanced Server est proposé en tant qu'ApsaraDB pour PPAS, une base de données relationnelle en tant que service sur Alibaba Cloud.
- VMware propose vFabric Postgres (également appelé vPostgres) pour les clouds privés sur VMware vSphere depuis mai 2012. La société a annoncé la fin de la disponibilité (EOA) du produit en 2014.
- En novembre 2013, Amazon Web Services a annoncé l'ajout de PostgreSQL à son offre de service de base de données relationnelle .
- En novembre 2016, Amazon Web Services a annoncé l'ajout de la compatibilité PostgreSQL à son offre de base de données gérée Amazon Aurora native du cloud .
- En mai 2017, Microsoft Azure a annoncé Azure Databases pour PostgreSQL
- En mai 2019, Alibaba Cloud a annoncé PolarDB pour PostgreSQL.
- Jelastic Multicloud Plate - forme en tant que service fournit un support PostgreSQL à base de conteneurs depuis 2011. Ils offrent la réplication automatisée maître-esclave asynchrone de PostgreSQL disponible à partir du marché.
- En juin 2019, IBM Cloud a annoncé IBM Cloud Hyper Protect DBaaS pour PostgreSQL .
- En septembre 2020, Crunchy Data a annoncé Crunchy Bridge .
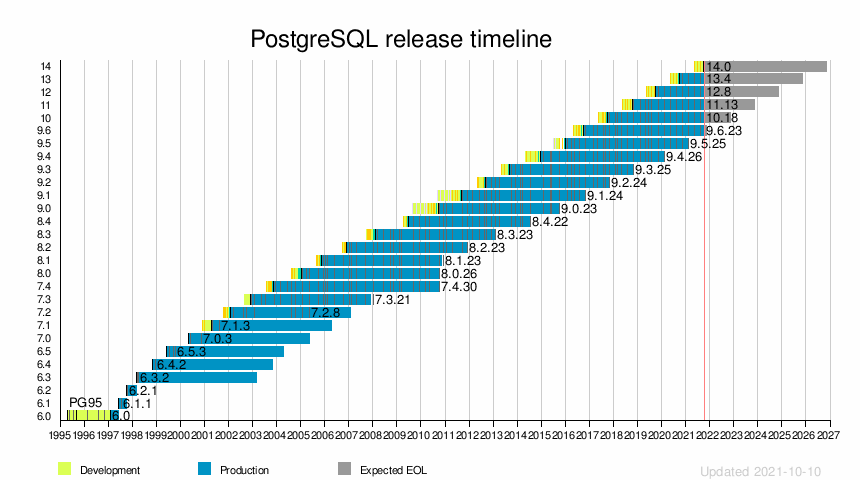
Historique des versions
| Sortie | Première sortie | Dernière version mineure | Dernière version | Fin de vie |
Jalons |
|---|---|---|---|---|---|
| 6.0 | 1997-01-29 | N / A | N / A | N / A | Première version formelle de PostgreSQL, index uniques, utilitaire pg_dumpall, authentification ident |
| 6.1 | 1997-06-08 | 6.1.1 | 1997-07-22 | N / A | Index multicolonnes, séquences, type de données monétaires, GEQO (GEnetic Query Optimizer) |
| 6.2 | 1997-10-02 | 6.2.1 | 1997-10-17 | N / A | Interface JDBC, déclencheurs, interface de programmation serveur, contraintes |
| 6.3 | 1998-03-01 | 6.3.2 | 1998-04-07 | 2003-03-01 | Capacité de sous-sélection SQL-92, PL/pgTCL |
| 6.4 | 1998-10-30 | 6.4.2 | 1998-12-20 | 2003-10-30 | VUES (alors uniquement en lecture seule) et RULES, PL/pgSQL |
| 6.5 | 1999-06-09 | 6.5.3 | 1999-10-13 | 2004-06-09 | MVCC , tables temporaires, plus de prise en charge des instructions SQL (CASE, INTERSECT et EXCEPT) |
| 7.0 | 2000-05-08 | 7.0.3 | 2000-11-11 | 2004-05-08 | Clés étrangères, syntaxe SQL-92 pour les jointures |
| 7.1 | 2001-04-13 | 7.1.3 | 2001-08-15 | 2006-04-13 | Journal d'écriture anticipée, jointures externes |
| 7.2 | 2002-02-04 | 7.2.8 | 2005-05-09 | 2007-02-04 | PL/Python, les OID ne sont plus nécessaires, internationalisation des messages |
| 7.3 | 2002-11-27 | 7.3.21 | 2008-01-07 | 2007-11-27 | Schéma, fonction de table, requête préparée |
| 7.4 | 2003-11-17 | 7.4.30 | 2010-10-04 | 2010-10-01 | Optimisation sur les JOIN et les fonctions d' entrepôt de données |
| 8.0 | 2005-01-19 | 8.0.26 | 2010-10-04 | 2010-10-01 | Serveur natif sur Microsoft Windows , savepoints , tablespaces , récupération à temps |
| 8.1 | 2005-11-08 | 8.1.23 | 2010-12-16 | 2010-11-08 | Optimisation des performances, validation en deux phases, partitionnement de table , analyse de bitmap d'index, verrouillage de ligne partagée, rôles |
| 8.2 | 2006-12-05 | 8.2.23 | 2011-12-05 | 2011-12-05 | Optimisation des performances, constructions d'index en ligne, verrous consultatifs, veille à chaud |
| 8.3 | 2008-02-04 | 8.3.23 | 2013-02-07 | 2013-02-07 | Tuples Heap seule, recherche en texte intégral , SQL / XML , les types ENUM, UUID types |
| 8.4 | 2009-07-01 | 8.4.22 | 2014-07-24 | 2014-07-24 | Fonctions de fenêtrage, autorisations au niveau des colonnes, restauration de base de données parallèle, classement par base de données, expressions de table communes et requêtes récursives |
| 9.0 | 2010-09-20 | 9.0.23 | 2015-10-08 | 2015-10-08 | Réplication de streaming binaire intégrée , veille à chaud , capacité de mise à niveau sur place, Windows 64 bits |
| 9.1 | 2011-09-12 | 9.1.24 | 2016-10-27 | 2016-10-27 | Réplication synchrone , classements par colonne , tables non journalisées, isolation de snapshot sérialisable , expressions de table communes en écriture, intégration SELinux , extensions, tables étrangères |
| 9.2 | 2012-09-10 | 9.2.24 | 2017-11-09 | 2017-11-09 | Réplication en streaming en cascade, analyses d'index uniquement, prise en charge native de JSON , gestion améliorée des verrous, types de plage, outil pg_receivexlog, index GiST partitionnés dans l'espace |
| 9.3 | 2013-09-09 | 9.3.25 | 2018-11-08 | 2018-11-08 | Travailleurs en arrière-plan personnalisés, sommes de contrôle des données, opérateurs JSON dédiés, LATERAL JOIN, pg_dump plus rapide, nouvel outil de surveillance du serveur pg_isready, fonctionnalités de déclenchement, fonctionnalités d'affichage, tables étrangères inscriptibles, vues matérialisées , améliorations de la réplication |
| 9.4 | 2014-12-18 | 9.4.26 | 2020-02-13 | 2020-02-13 | Type de données JSONB, instruction ALTER SYSTEM pour modifier les valeurs de configuration, possibilité d'actualiser les vues matérialisées sans bloquer les lectures, enregistrement/démarrage/arrêt dynamique des processus de travail en arrière-plan, API de décodage logique, améliorations de l'index GiN, prise en charge des énormes pages Linux, rechargement du cache de la base de données via pg_prewarm , réintroduisant Hstore comme type de colonne de choix pour les données de style document. |
| 9.5 | 2016-01-07 | 9.5.25 | 2021-02-11 | 2021-02-11 | UPSERT, sécurité au niveau des lignes, TABLESAMPLE, CUBE/ROLLUP, GROUPING SETS et nouvel index BRIN |
| 9.6 | 2016-09-29 | 9.6.23 | 2021-08-12 | 2021-11-11 | Prise en charge des requêtes parallèles, améliorations de l'encapsuleur de données étrangères (FDW) PostgreSQL avec le tri/jointure pushdown, plusieurs veilles synchrones, aspiration plus rapide d'une grande table |
| dix | 2017-10-05 | 10.18 | 2021-08-12 | 2022-11-10 | Réplication logique, partitionnement déclaratif de table, parallélisme de requête amélioré |
| 11 | 2018-10-18 | 11.13 | 2021-08-12 | 2023-11-09 | Robustesse et performances accrues pour le partitionnement, transactions prises en charge dans les procédures stockées, capacités améliorées pour le parallélisme des requêtes, compilation juste à temps (JIT) pour les expressions |
| 12 | 2019-10-03 | 12.8 | 2021-08-12 | 2024-11-14 | Améliorations des performances des requêtes et de l'utilisation de l'espace ; Prise en charge des expressions de chemin SQL/JSON ; colonnes générées ; améliorations de l'internationalisation et de l'authentification ; nouvelle interface de stockage de table enfichable. |
| 13 | 2020-09-24 | 13.4 | 2021-08-12 | 2025-11-13 | Gain de place et gains de performances grâce à la déduplication des entrées d'index B-tree, performances améliorées pour les requêtes utilisant des agrégats ou des tables partitionnées, meilleure planification des requêtes lors de l'utilisation de statistiques étendues, aspiration parallélisée des index, tri incrémentiel |
| 14 | 2021-09-30 | 14,0 | 2021-09-30 | 2026-11-12 | Ajout des clauses SEARCH et CYCLE standard SQL pour les expressions de table communes, permettant d'ajouter DISTINCT à GROUP BY |
Voir également
- Comparaison des systèmes de gestion de bases de données relationnelles
- Évolutivité de la base de données
- Liste des bases de données utilisant MVCC
- LLVM (llvmjit est le moteur JIT utilisé par PostgreSQL)
- Conformité SQL
Les références
Lectures complémentaires
- Obé, Régina ; Hsu, Leo (8 juillet 2012). PostgreSQL : opérationnel . O'Reilly . ISBN 978-1-4493-2633-3.
- Krosing, Hannu ; Roybal, Kirk (15 juin 2013). Programmation PostgreSQL Server (deuxième éd.). Édition Packt . ISBN 978-1-84951-698-3.
- Riggs, Simon ; Krosing, Hannu (27 octobre 2010). PostgreSQL 9 Administration Cookbook (deuxième édition). Édition Packt . ISBN 978-1-84951-028-8.
- Smith, Greg (15 octobre 2010). PostgreSQL 9 hautes performances . Édition Packt . ISBN 978-1-84951-030-1.
- Gilmore, W. Jason ; Treat, Robert (27 février 2006). Débuter PHP et PostgreSQL 8 : de novice à professionnel . Apress . p. 896. ISBN 1-59059-547-5. Archivé de l'original le 8 juillet 2009 . Consulté le 28 avril 2009 .
- Douglas, Korry (5 août 2005). PostgreSQL (deuxième édition). Sams . p. 1032. ISBN 0-672-32756-2.
- Matthieu, Daniel ; Pierres, Richard (6 avril 2005). Début des bases de données avec PostgreSQL (deuxième édition). Apress . p. 664. ISBN 1-59059-478-9. Archivé de l'original le 9 avril 2009 . Consulté le 28 avril 2009 .
- Worsley, John C; Drake, Joshua D (janvier 2002). PostgreSQL pratique . O'Reilly Media . p. 636 . ISBN 1-56592-846-6.
Liens externes
-
Site officiel

- PostgreSQL chez Curlie
- PostgreSQL sur GitHub